Concurrent modification of shared data can be a problem in any distributed system regardless of what data store you are using. With ACID-compliant relational databases, a common tactic is to use pessimistic locking at the table or row level. Most NoSQL data stores do not have a pessimistic lock operation, and even when they do, it is often considered a performance hazard. So, most applications do not lock objects before writing them to a NoSQL datastore (or they use an external lock of some sort). This can quickly become a problem when you have a distributed system with write contention, as shown in the figure below:
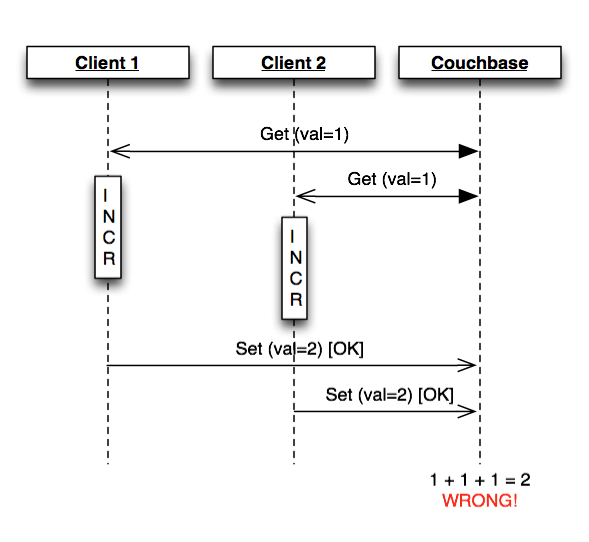
One of the nice features of Couchbase is its “CAS” operation. This provides the ability to do an atomic check-and-set operation. You can set the value of a key, providing the last known version identifier (called a “CAS value”). The write will succeed if the document has not been modified since you read it, or it will fail if it has been modified and now has a different CAS value.
Using this operation, we can easily build a higher-level operation to provide optimistic locking on our documents, using a CAS retry loop. The idea is simple: get the latest version of the document, apply your update(s), and write it back to Couchbase. If there are no conflicts, then all is well, and you can move on. If there is a conflict, you re-get the latest version of the document, fully reapply your modifications, and try again to write the document back to Couchbase. Repeat until the write succeeds.



